I’m sure all of us, when learning something new, have had moments of inspiration where we’d think, “Oh wow! This idea makes sense and is so brilliant.” It’s these moments that I always look forward to, and what attracted me to machine learning was that I had these moments almost every day, only motivating me to keep learning more and more. When I think about my Aha moments, they are often the experiences where I encountered the simplest of ideas. One such concept is Bayes’ theorem, which forms the foundation for many more important ideas used in ML, data science, and statistics. Let’s explore what Bayes theorem is and why it’s so brilliant.
Taking a step back
To understand what Bayes theorem is, it’s important first to review basic probability, something I’m sure we’ve all studied in high school math. Probability is essentially a way of dealing with uncertain events. These events have some randomness associated with them and don’t follow a fixed process. Let’s look at the most common probability example: the coin toss. Let’s say I toss a coin; how likely is it to come up as heads? To calculate this, we divide the number of desired outcomes by the total number of possible outcomes. When I flip a coin, there are two possible outcomes – heads or tails. Our desired outcome is just that one where I get heads, so we say
 = \frac{\text{number of desired outcomes}}{\text{total number of equally possible outcomes}} = \frac{1}{2}=0.5")
")
Let’s look at another popular example: rolling a dice. Suppose I have a six-sided dice, what is the chance that I roll a 1? Simply using the formula above, its 
 = P(\text{2 OR 4 OR 6}) = P(\text{2}) + P(\text{4}) + P(\text{6})")

What even is probability?
Great, so using this probability formula, one can calculate a probability value for any basic scenario. But what does this concept mean? Most of us in high school (at least me!) just saw probability as another math formula you plug and play. After seeing its applications in data science and machine learning, I better understood what probability means and why it is relevant to life.
Looking back to the early research by mathematicians and philosophers, there have been many different probability interpretations. The probability formula I showed previously is called the “classical interpretation” of probability, which is the first rigorous effort to formalize this idea. Another popular interpretation is the “frequentist interpretation,” which states that a probable event occurs frequently. So, if I now look at the coin toss from a frequentist point of view, the way I would calculate the
 = \frac{\text{number of times coin is heads}}{\text{total number of times I flipped the coin}}")
In this case, if I flip the coin just 5-10 times, I may not get the same 0.5 probability as in the classical definition. For example, if I do five experiments where I see two heads and three tails, then the frequency of heads is 
Another interpretation of probability is the BAYESIAN interpretation. This interpretation arises from the ideology that we, as humans, like to have initial beliefs or opinions about something. Only through experiences and collecting more information do we update this belief. Here, the belief is synonymous with probability. For example, I believe that Pizza Hut makes the best pizza ever, so I say that ")
Bayes Theorem
Bayes theorem is a straightforward formula for updating beliefs. A related idea to this theorem is that of “conditional” probability. Recall a normal probability asks the question, “What is the chance that X occurs?”. Conditional probability asks the question “What is the chance that X occurs, given that we know Y occurs?” which is conventionally represented by ")
 = \frac{P(X \text{and} Y \text{occurs})}{P(Y)}")
This equation probably doesn’t make sense at first sight so let’s do a simple example.
The Pizza Party
Suppose I’m hosting a party for my 100 friends and I need to decide what food to order. I know that some of my friends are vegetarians while some are non-vegetarian. I also know that some like pizza, and some hate pizza. I sent a survey to all my friends to collect this information, and I’ve summarized the results into a nice little table below.
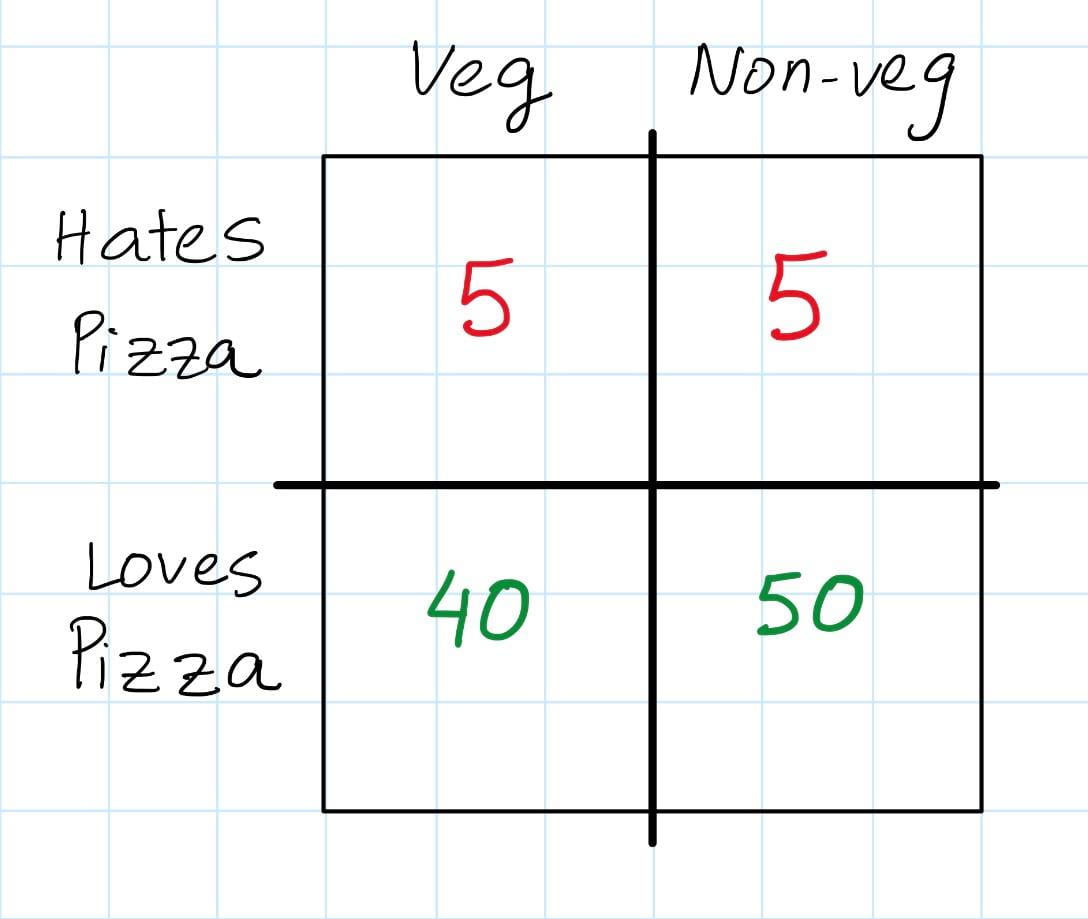
As a warm-up, what’s the probability someone loves pizza? It’s just
 = P(\text{Loves pizza and is vegetarian}) + P(\text{Loves pizza and is non-vegetarian})")

Great stuff! Now, here comes a slightly trickier problem: what is the probability that someone loves pizza, given that they are a vegetarian or ")
The way I think about this is that if I’ve been given information that the person is a vegetarian, then I can focus on the group of vegetarian people and ignore the non-vegetarians. Instead of focusing on all my 100 friends, I’m focusing on just my 45 vegetarian friends. Now, in my vegetarian friend group, what is the probability that someone loves pizza? Simple, it’s just 
 = \frac{P(\text{Loves Pizza and Vegetarian})}{P(\text{Vegetarian})}")

As you can see, this is the same as the conditional probability formula where Y = “Vegetarian” and X = “Loves pizza”. To reiterate, by dividing by ")
Now to bring the concept home and connect it to the bigger picture, let’s do one last interesting problem. Suppose I was in a different scenario – I got information that the person loves pizza, and I want to know the probability that this person is a vegetarian. So now instead of ")
 = \frac{P(\text{Loves Pizza and Vegetarian})}{P(\text{Loves Pizza})}")
Compare this equation to the equation from the previous problem:
Now we can do something interesting here. While both equations calculate a different conditional probability, both have the same numerator, which is P(Loves Pizza and Vegetarian). If I do some basic algebra on [Equation 1], I’ll find that
 \times P(\text{Loves pizza}) = P(\text{Loves Pizza and Vegetarian})")
I can plug this back into [Equation 2] to get that
 \times P(\text{Loves pizza})}{P(\text{Vegetarian})}")
and Ta-Da! This is the Bayes Theorem for my pizza party example.
You’re probably super confused right now or wondering why on earth I did this tedious math. Well, let me summarize the above ugly equations into something neater:
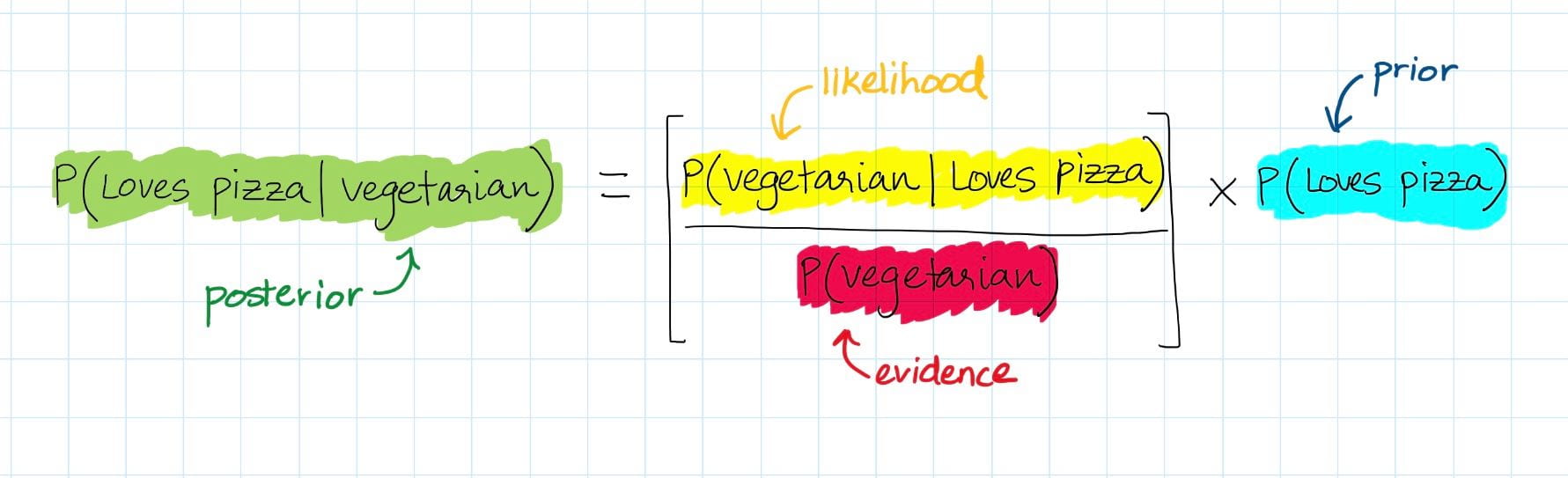
On the right side of the equation, we have the probability of someone loving pizza, ")
}{P(\text{Vegetarian})}")
")
Why is this equation cool? Because recall that originally, we calculated that  = 0.89")
Conditional probability, Bayes theorem, and Bayesian inference are fundamental concepts in machine learning. Bayesian thinking is valuable because it allows us to factor previous knowledge into our beliefs, allowing us to model dynamic scenarios and generate useful insights from data. In future posts, I hope to delve more in detail into the different applications of these concepts.
One thought on “Bayes Theorem – A primer”