[How to improve marking and feedback is one of the things that we in the Digital Assessment Advisory are asked about the most. As well as the workload involved, especially for large cohorts, the challenge is to ensure that assessment is reliable (there is agreement between a team of markers and consistency of marking over time), valid (the assessment measures what it aims to measure) and comparable (they represent standards that have currency with universities and employers and remains consistent over time).
Since marking is such a complex, and often very time-consuming task, it is no wonder that any degree of digital automation is appealing for many – especially those with large cohorts to mark. However, as Mark Andrejevic notes, the ‘fantasy of automatic judgement’ can be deceptive; there are still human (and potentially contestable) decisions to be made. That is the inescapable and necessary work of academia. What is possible though, within Digital Assessment technology, is to combine the affordances of automation with human decision-making in order to improve assessment for students and markers.
Multiple Choice Questions (MCQs) and online rubrics represent different ends of the scale in the automation or standardisation of marking and, if well-designed, can help minimise some of the marking challenges in commonly used assessment types.
MCQs
Interactive online MCQs are easy to grade automatically (arguably the only way you would want to grade them!). These are frequently used as knowledge-based assessment in STEM based subjects and normally represent around 10% of the total assessment load (see the Assessment Operating Model).Whilst the ease may be in the marking, the challenge with MCQs is in creating effective questions – ones that are a sufficiently robust assessment of a students’ knowledge base. There are a few potential pitfalls in MCQ creation that can undermine this ambition and inadvertently providing ‘giveaways’, making answers easy to guess. Other question types we can include in the category of MCQs are Single Best Answers (SBAs) which require the student to select the answer that it the best fit from a set of options and Extended matching items/questions (EMQs) where the student is presented with a theme and scenarios relating to that theme plus a set of potential answers that are the best fit for each scenario. The question asks the student to match correct option to each scenario. Both of these can assess higher level learning than the standard MCQ, which usually tests factual recall. The choice of question type really depends on what the purpose of your assesssment is. Last year, the Digital Assessment Team worked with Jacopo Buti to present a session for the Eastman Dental Institute Away day on MCQs (both writing them and creating them online) as these are frequently used in clinical practice assessments. From there, we developed a UCL-wide workshop, Designing effective Multiple Choice Questions (online), which we are running again this year. Here is Jacopo’s case study:
Jacopo Buti (Eastman Institute) on Designing effective MCQs for Periodontology Assessments
RUBRICS

Whilst the focus for MCQs moves from marking to question creation, when it comes to other types of assessment such as written work, projects and so on, the challenge is not only in creating the assessment but in marking and feedback. It may be assumed that everyone ‘knows’ what work of a particular level or quality looks like, but as anyone who has been involved in marking student work can vouch, this is very often not the case, or there may be stark differences in interpretations of ‘quality’. Marking involves academic judgement which is difficult to capture in a mechanical way and it is also prone to human fallibility. There will always be an element of subjectivity involved; predispositions and circumstances – unconscious or conscious bias, marking load, not to mention the all too human experiences of mood, tiredness, hunger – can impact on student outcomes. Even if we go down the AI route, there are pedagogical and demographic biases embedded in AI systems, as Audrey Watters and others have demonstrated.
One way to navigate this tricky terrain is the use of rubrics. Rubrics are a marking grid which combine criteria, grades & feedback into a single scoring matrix. They help provide consistency and efficiency in marking, criteria and support learners in understanding how their performance will be judged.
A well-designed rubric is clearly written and measures what it intends to measure i.e., it aligns intended learning outcomes with assessment criteria, provides appropriate weighting to each element of the students’ performance. The upfront effort involved in creating an effective rubric is worth it, in terms of clarity, consistency and speed of marking, according to Adam Gibson and Scott Orr (UCL Institute of Sustainable Heritage and UCL Medical Physics and Biomedical Engineering) and Michelle Hann (Great Ormond Institute of Child Health), who have been using them for some time.
Adam Gibson and Scott Orr Rubrics Case study
Michelle Hann rubrics case study
Rubric case study from Michelle de Haan (Great Ormond Institute of Child Health)
At University of the Arts a institute wide rubric was agreed which provided a customisable template for every programme to use. This has since been rolled out at other institutions such as London South Bank university (for both STEM and humanities). The development of these shared rubrics involved institute wide consultation. In 2015, Dilly Fung at UCL also produced a guide on Student Assessment Criteria for all levels of UG and PG taught programmes (which Adam Gibson refers to in the case study above).
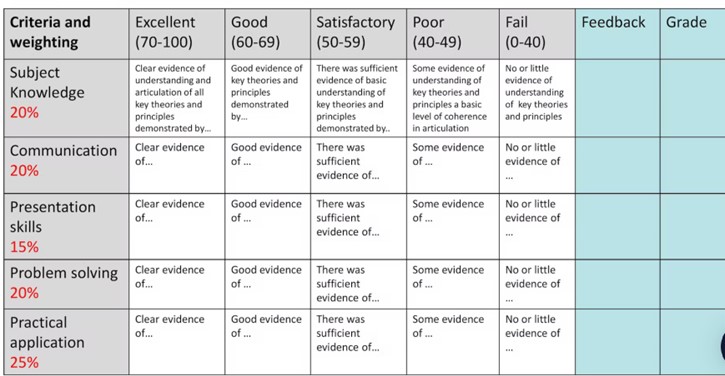
Rubrics can be designed in different ways – both as a standard analytical matrix which provided detailed feedback and grades, as in the image below, or as a more holistic version which gives general more quantitative feedback – depending on your requirements. They are easy to set up online , for example, via Moodle or AssessmentUCL and, whilst automation is probably a loose word to describe them, rubrics do provide a set of prepopulated descriptors which markers use as a basis for making judgements on the student’s performance. They can also calibrate final grades from a series of points given to individual criteria. However, it’s always good to allow a bit of customisation (i.e. ability to adjust the final grade if necessary) and to provide a free text space for further feedback.
Example template of standard analytical matrix
It is important is to ensure that all participants (markers and students) have a shared understanding of the marking criteria included in the rubric before use. Testing it out in advance of marking is key – for example, through a marking standardisation exercise – to clarify any grey areas or different interpretations between markers. Getting feedback from students on whether it makes sense to them is also good practice. Once you have an agreed rubric, students will need further support in interpreting the marking criteria and understanding how to use the feedback to improve their work going forward (as with any marking criteria and feedback).
One criticism of rubrics is that they encourage students to ‘work to the rubric’, thus perhaps imposing limits on their achievements, but remember we are talking about assessing intended or stated learning outcomes. There should always be enough scope within module and programme design for incidental or additional learning. But we may not be able to assess these in a formal way because they will be different and unpredictable for each student. Students need to know what the minimum pass level is but there should always be opportunities and positive encouragement to exceed these. The marking criteria on a rubric will tell students what excellence looks like and feedback will tell them how to achieve it.
The Digital Assessment team will be running a Rubrics: removing the glitch in the assessment matrix? (online workshop) on Tuesday 6th December.